
Analyzing the Carbon Footprint of AI & Machine Learning
Let's try to analyze the carbon footprint of AI & machine learning by minimizing them by adopting methods such as reducing emissions from data centers.

Introduction
The AI and Machine Learning (ML) industry have been growing rapidly in recent years. The data center industry has also been expanding, which means that many more machines are being turned on at any given time to train these algorithms. As a result of both these factors combined, the amount of energy required by machine learning and AI is expected to increase significantly over time. Let’s try to determine if there are ways we can analyze the carbon footprint of AI & machine learning by adopting methods such as reducing emissions from data centers. This can be done by analyzing how much energy different algorithms consume as well as how much energy is consumed during ai inference vs training for popular algorithms like neural networks, convolutional neural networks (CNNs), restricted Boltzmann Machine (RBM) models, etc. The analysis shows that there are efficient ways to train algorithms with less energy consumption, highlighting the crucial role of tailored energy software development services in achieving more sustainable AI practices.
The Meta-Analysis
The first step in conducting a meta-analysis is to clearly define the purpose and scope of your research. In this case, you’re looking at how AI and machine learning can impact the carbon footprint of an organization. This means that you need to think about how much data you have, how many studies you want to analyze (and what criteria), who will be responsible for collecting data, etc.
The goal of a meta-analysis is to synthesize all existing literature on a particular topic into one cohesive body of work with implications for future research or practice. To do this effectively requires careful planning and execution so that results are both valid and meaningful—you don’t want all those studies looking different from each other.
Decrypting the Carbon Footprint of AI & Machine Learning By Meta-Analysis
A meta-analysis is a statistical summary of the results of multiple studies. It’s important for researchers to understand how their findings compare to those in other studies, so they can make sure they’re not cherry-picking their data or making any significant errors.
In this case, we want to look at how AI & Machine Learning impact carbon emissions and energy consumption. We need to be able to compare our results with those reported by others before we can draw any conclusions about what impact these technologies have on climate change (or whatever else).
The Collective Carrying Capacity of All Data Centers Globally
The collective carrying capacity of all data centers globally is projected to grow by 50% by 2022.
This growth can be attributed to the rise in popularity and use of AI, which requires more powerful computers than ever before. It’s also worth noting that many companies are choosing to build their own private cloud rather than rely on public clouds like Google Cloud or Amazon Web Services (AWS).
This increase in computing power will not only require more electricity but also larger amounts of cooling equipment to keep everything running smoothly. It’s important for companies who want their products ready when consumers want them—but it’s also important for us as a society because we need this technology.
How much Energy Does a Data Center Consume?
The amount of energy consumed by data centers is staggering. In fact, it’s more than the entire aviation industry and nearly as much as the transportation and agriculture industries combined.
The reason for this is simple: data centers require enormous amounts of electricity to power their operations and keep them running 24/7—and they use a lot more electricity than any other industry in the world! Data centers consume so much power that if they were an independent country (or city), they would rank No. 3 on our list of most polluting countries behind China and India (which both have over 1 billion people).
How much Energy Does AI Consume?
AI consumes energy when it is trained. The more data you provide to an AI, the more accurately your model will predict future outcomes. This requires a lot of computing power and can be expensive if you’re using big-data methods like neural networks or deep learning (a type of machine learning). When training an AI, you have to take into account all possible inputs and outputs—it’s not just about memorizing rules but also understanding them completely. This means consuming large amounts of electricity in order to run tens or hundreds of thousands of simulations per second on computers with high-performance processors and large amounts of RAM capacity.
Running an AI involves running some kind of software program that has been trained by another person using specialized algorithms like neural networks or Bayesian inference; this process usually involves running through all possible combinations (or “hypotheses”) before determining which one is most likely to lead toward profitable outcomes for customers who use our product/service/etcetera…and then taking those findings into account when making decisions about how much money we should spend on buying new supplies from suppliers who produce them cheaper than us because they’re located closer than us but sell at higher prices due directly due having lower wages being paid workers who work harder than anyone else!
How Much Energy Does it take to Train AI?
The amount of data required to train AI is exponentially increasing. In the past, it took up to 10 years for one person’s life experience to equal what was stored in a single hard drive. Today, it takes less than one hour for every human on earth to create more data than was available in all previous history combined (5 exabytes).
The problem with this exponential growth is that we only have so much storage—and our ability to store more information doesn’t keep pace with our need for it.
In fact, according to research by techtarget.com, by 2025 we’ll need much more space (nearly 163 zettabytes) just for storing videos and photos.
This means that even if you had unlimited amounts of money or resources available today (which many people don’t), there would still be limits on how much information could be stored before running out completely.
How much Energy Does it take to Run Inference with AI?
The inference is the process of using an AI model to make a prediction. It’s one of the most common uses cases for AI, and it happens when you feed your trained model with new data.
The inference is often used as part of training or testing an ML system (also called “supervised learning”), but it can also be used independently. For example, if you have an existing neural network and want to use it on new images without retraining it first, this would be considered inference rather than training; in this case, you might use Google Cloud Vision API instead of directly feeding your trained model into Google Translate.
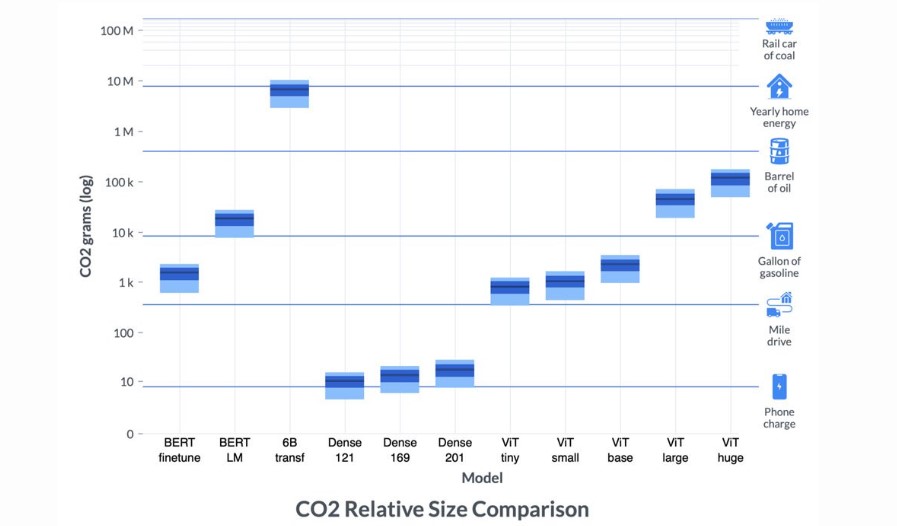
Emissions Caused by Training of Popular Algorithms
The amount of emissions caused by training popular algorithms is not trivial. For example, if you train an ordinary neural network on the MNIST dataset, it will consume about 30 gigabytes of RAM and 2 gigawatts of electricity—and that’s for just one layer!

Some Popular Datasets and Their Emissions
The datasets used in the study were:
- The ImageNet dataset, which contains over 1 million images and is widely accepted as one of the most important datasets for training computer vision algorithms.
- Amazon Web Services (AWS) cloud computing data is stored on S3 buckets that contain information about how many hours AWS has been used by different applications such as image processing or machine learning code, or how much storage space these applications consume.
Discussion
There are many ways to reduce the carbon footprint of AI. The amount of energy used by AI is a trade-off between performance and efficiency, so we need to be able to measure the carbon footprint of AI and compare it with other technologies. We also need a way to evaluate how many times more expensive it would be for an organization or company if they relied solely on solar energy versus having an electric car charging station at their offices or homes.
A great example of this was demonstrated by Google in September 2021. At this time, Google partnered with the United Nations and Sustainable Energy for All and came up with a new 24/7 Carbon-Free Energy Compact that delineates a set of principles and actions amongst all their stakeholders. They plan to formulate a shared energy ecosystem wherein one can take steps to adopt, enable, and advance 24/7 CFE (Consent for Establishment) as a means to fully decarbonize electricity.
In fact, Google Cloud has set sustainable goals for all its services which will be powered by carbon-free sources all the time by the end of 2030.
They have also implicated a plan for renewable energy generation at their data centers: they will use 100% renewable sources such as wind and solar power instead of fossil fuels such as coal or natural gas (which release greenhouse gases). They estimate that this will save them approximately 700 million kilowatt hours each year—or over 1 billion pounds worth!
An ML algorithm with two weights can be trained with an equal or lower amount of emissions than an ML algorithm with one weight.
If a two-weight ML algorithm can be trained with an equal or lower amount of emissions than an ML algorithm with one weight, then it makes sense that there would be no need for new models and algorithms. In other words, we don’t need to worry about building new models if we already have existing ones that can handle the job just fine.
This is why many researchers are now experimenting with using existing AI models in order to reduce their carbon footprint by using them instead of training new ones. For example:
The University College London has developed an algorithm that uses deep learning techniques from image recognition software such as Google’s TensorFlow framework (which was developed by Google Brain) plus convolutional neural networks (which were originally created by Alex Krizhevsky at University College London). This combination allows us to train our computer vision system without having any additional hardware costs associated with running these types of programs–which means less electricity being used up by running all this stuff.
Conclusion
The data center is a huge energy consumer. AI algorithms are also becoming more popular, but not as much as data centers. This could be because the training of an ML algorithm involves much less memory and storage space than training a traditional neural network (NN) which requires around 100x more memory than GPUs currently have. However, there’s still an opportunity for researchers to make progress in reducing the necessary size of training datasets by using techniques like multi-stage learning or repeated weighted averaging over epochs (or mini-batches).

