
GPTBot crawler & GPT-5 plans launched
GPTBot is launching new crawler and GPT-5 plans to help businesses and developers quickly and easily access powerful AI technology.

August 10, 2023, New Jersey: Artificial intelligence leader OpenAI has introduced its latest innovation, the “GPTBot” web crawling tool, with an eye towards enhancing upcoming iterations of the ChatGPT model. In a recent blog post, OpenAI revealed that the data gleaned from web pages crawled by GPTBot could potentially contribute to refining the accuracy and expanding the capabilities of future ChatGPT models.
GPTBot, akin to a web spider, functions as a web crawler to index the content of websites across the vast expanse of the internet. This technology, often utilized by search giants like Google and Bing, is pivotal in ensuring that websites feature prominently in search results.
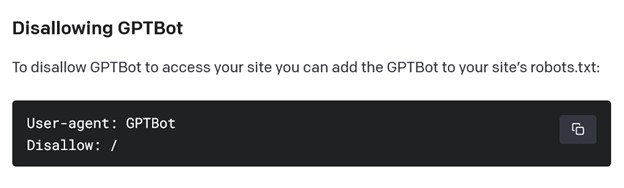
OpenAI clarified that GPTBot’s activities will focus solely on collecting publicly available data from the World Wide Web. However, the tool will be programmed to exclude sources featuring paywalled content, personally identifiable information, or text that violates OpenAI’s policies. Website owners can restrict GPTBot’s access by inserting a simple “disallow” command into a standard server file.
This announcement comes on the heels of OpenAI’s recent application to trademark “GPT-5,” indicating its intentions to follow up on the current GPT-4 model. The application, submitted to the United States Patent and Trademark Office on July 18, encompasses the use of “GPT-5” in various AI-related applications such as human speech and text processing, audio-to-text conversion, and voice and speech recognition.
Notwithstanding the anticipation surrounding GPT-5, OpenAI CEO Sam Altman tempered expectations by revealing that the company is far from commencing GPT-5’s training. Altman cited the need for comprehensive safety audits as a prerequisite before embarking on the next training phase.
Recent concerns have emerged about OpenAI’s data collection practices, with specific emphasis on copyright and consent. In June, Japan’s privacy regulatory authority cautioned OpenAI against acquiring sensitive data without proper authorization. Similarly, Italy suspended the use of ChatGPT in April, alleging violations of European Union privacy laws.
Complicating matters further, OpenAI is facing legal challenges. In late June, a class-action lawsuit was filed by 16 plaintiffs who claimed that the company accessed private information from interactions with ChatGPT users. If substantiated, these allegations could potentially place OpenAI and co-defendant Microsoft in violation of the Computer Fraud and Abuse Act, a law with established precedents in web-scraping cases.
While OpenAI continues to push the boundaries of AI capabilities with the introduction of GPTBot and the aspirations for GPT-5, it navigates a landscape rife with both potential advancements and challenges surrounding data privacy and legal compliance.

