Compare AI Answers Side-by-Side
Different models = different answers. See the full picture before you decide.
![]() Lead-Gen now on Auto-Pilot with
Build My Campaign
Lead-Gen now on Auto-Pilot with
Build My Campaign
Explore how different LLMs respond to the same prompt, comparing accuracy, tone, and insights to understand their strengths and limitations.

Compare AI Answers Side-by-Side
Different models = different answers. See the full picture before you decide.
You type the same question into ChatGPT, Gemini, Claude, and Perplexity. Four different answers come back. Some overlap, some contradict, and at least one probably says something you did not expect. Welcome to the weird, fascinating, and professionally relevant reality of large language model behavior.
This is not a bug. It is a design feature, and understanding it can provide a competitive advantage for marketing, content, and demand generation teams that optimize for AI visibility.
Every LLM is trained differently. The training data, fine-tuning process, safety layers, system prompts, and retrieval mechanisms all vary. When you send a prompt to GPT-4o versus Claude 3.5 Sonnet versus Gemini 1.5 Pro, you are essentially asking three researchers who studied at different universities, in different decades, with access to different libraries.
There is also the matter of temperature settings. Most LLMs have a “temperature” parameter that controls output randomness. Higher temperature means more creative and variable outputs. Lower temperature pushes the model toward more deterministic, consistent answers. Most consumer-facing products sit somewhere in the middle, which means two identical prompts submitted minutes apart can return meaningfully different results from the same model.
Researchers from Stanford and UC Berkeley found that model performance is far from static; in fact, GPT-3.5’s ability to handle specific logic and coding tasks shifted significantly between March and June 2023. These fluctuations occurred without any explicit updates communicated to users, proving that even for the most advanced systems, consistency is often aspirational.
Here is what actually happens when you submit a prompt:
This means LLMs are not “looking up” answers the way a search engine does. They are generating text that is statistically likely to follow your prompt, based on patterns learned during training. This is why two models can both be “correct” while saying different things: they are optimizing for plausible continuation, not objective truth retrieval.
Compare AI Answers Side-by-Side
Different models = different answers. See the full picture before you decide.
Retrieval-Augmented Generation (RAG) partially changes this. Models like Perplexity layer live web search on top of their base language model, pulling in fresh sources before generating a response. That is why Perplexity’s answers often feel more current and are more heavily sourced, and it is also why understanding Perplexity SEO matters if you want your content in the mix.
Here is where things get genuinely interesting. We ran the exact same prompt across ChatGPT, Gemini, Perplexity, and Claude:
Prompt: “What is the best strategy for improving pipeline velocity in a mid-market SaaS company?”
Same question. Same words. Four very different answers in structure, tone, framing, and strategic emphasis. Here is what came back.
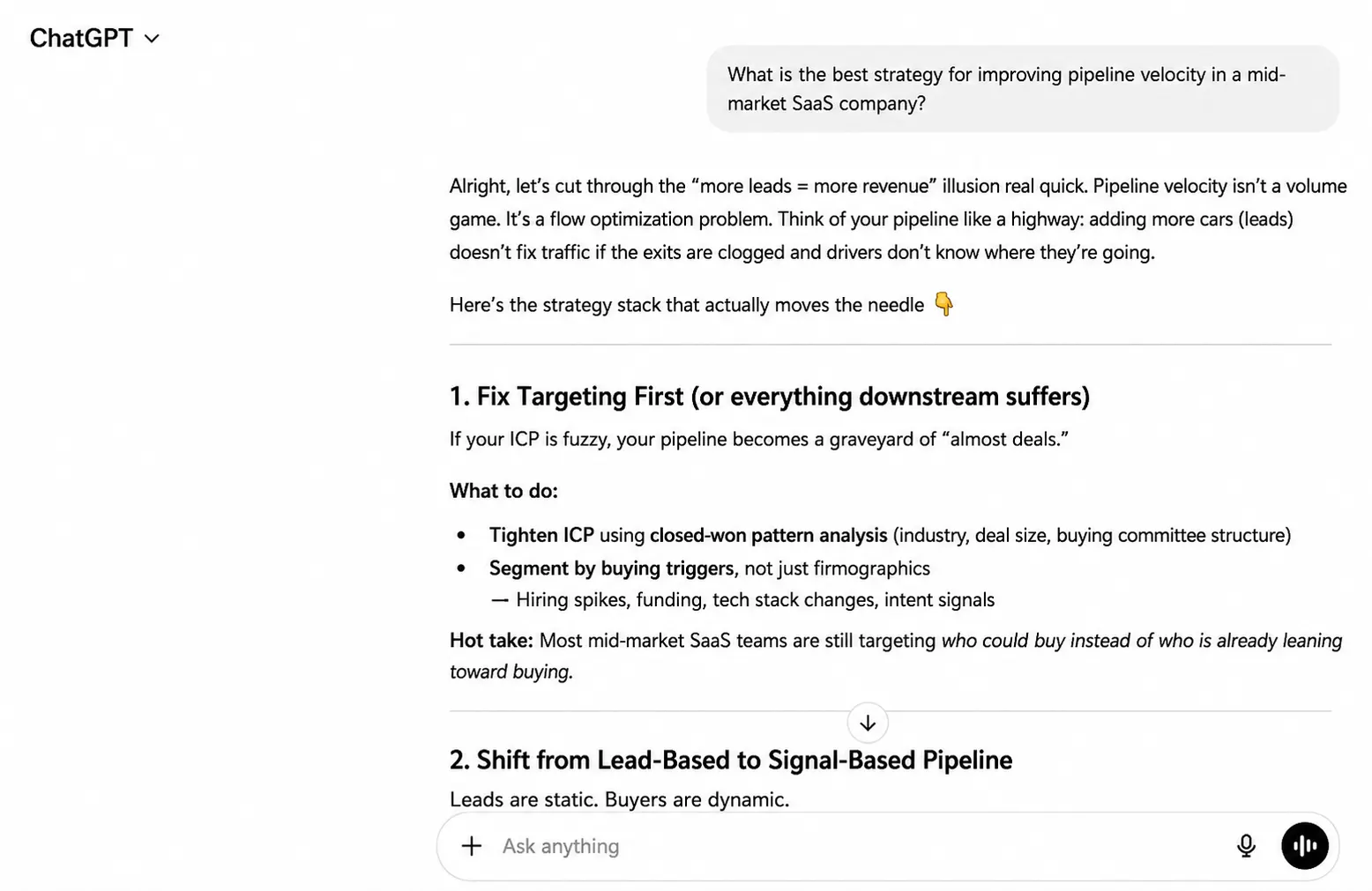
ChatGPT opened with a hot take and a highway metaphor before delivering a numbered strategy stack. It framed the answer around a highway metaphor (adding more cars does not fix a clogged exit) then structured the rest as a numbered strategy stack with bold section headers.
Notice what it did not do: hedge. It assumed authority and delivered a playbook. This is ChatGPT’s default register: confident, energetic, and formatted for skimmability. For content teams, this is a signal. If your buyers use ChatGPT, your content needs to be opinionated and built around clear mental models. This is a core component of generative engine optimization where being “quotable” is the goal.

Gemini opened with context before tactics. It acknowledged that mid-market deals involve “multiple stakeholders and longer procurement cycles than SMB” before prescribing anything. It then anchored the entire response in a formula:
Velocity= (Opportunities ×Deal Value ×Win Rate)/(Sales Cycle Length)
Gemini’s framing reflects its design lineage: it is comfortable with formulas and defaults to systemic thinking. To influence this, brands need research-backed models and structured writing.
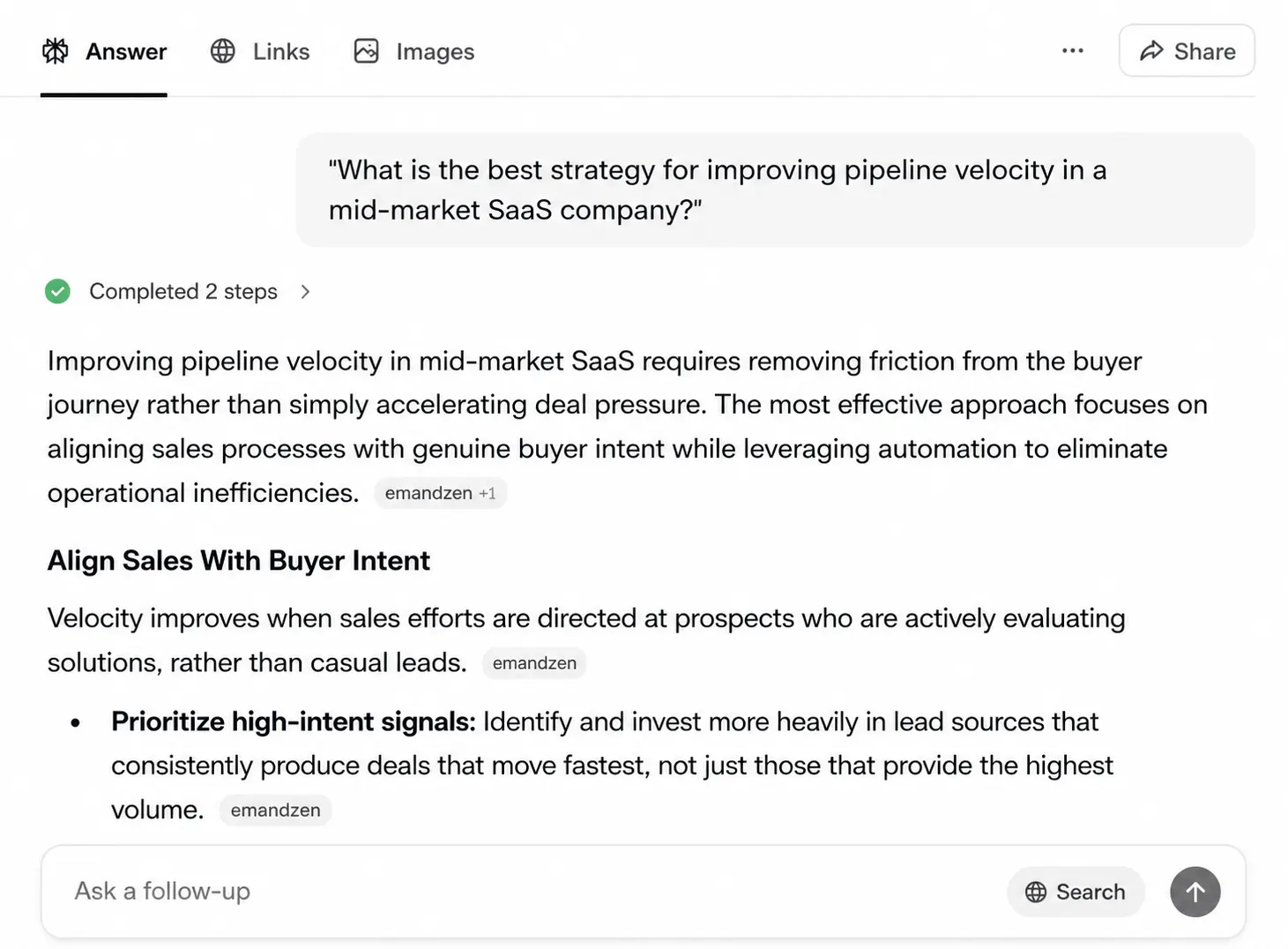
Perplexity completed research steps before generating a response. The interface showed “Completed 2 steps” before the answer appeared. More importantly, it cited sources inline. This is RAG in action.
The strategic implication here is significant. Showing up in Perplexity is a fundamentally different problem than showing up in ChatGPT. You need to be discoverable in real time (which is precisely why answer engine optimization has become a distinct discipline). Your content needs to exist, rank, and be structured clearly enough for a live system to find it.

Claude opened with the math but focused on operational levers. It recommended standardizing sales methodology using MEDDIC (Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, Champion) or SPICED (Situation, Pain, Impact, Critical Event, Decision). It flagged that most mid-market losses happen because “pain wasn’t properly qualified” (a diagnosis, not just a prescription).
Claude is dense and methodical. It reads like a senior revenue leader writing an internal memo, not a keynote speaker.
| Feature | ChatGPT | Gemini | Perplexity | Claude |
| Opening Move | Hot take + Metaphor | Context + Equation | Friction framing | The math first |
| Structural Style | Energetic listicle | Analytical framework | Sourced synthesis | Operational memo |
| Tone | Coach / Persuader | Consultant | Researcher | Senior Operator |
| Source Behavior | Internal Training | Light sourcing | Heavy inline citations | Internal Logic |
This same model-comparison logic applies beyond text-based LLMs — for instance, those evaluating AI video generation tools can explore a detailed Seedance 2.0 vs Kling 3.0 breakdown to understand how different architectures produce meaningfully different creative outputs.
LLMs do not hallucinate randomly. They hallucinate along the lines of their training data. If a model saw thousands of documents citing McKinsey, Gartner, and HBR, it will pattern-match toward those entities when generating authoritative-sounding content.
This is where entity-first SEO becomes genuinely strategic. LLMs associate authority with entities, not just keywords. A Semrush’s 2024 AI Overviews Study found that AI-generated answers heavily favor domains with high authority scores and long-form content. Furthermore, what schema markup does for AI search is critical; it helps models parse and represent your content accurately, reducing the “noise” the model has to filter through.
Here is something most people overlook: the ChatGPT or Claude you use on the public web is not the same system your enterprise clients are using internally.
Enterprise deployments often include custom system prompts that set behavioral guardrails and preferred source domains. A company might instruct their internal AI assistant to only cite verified internal documentation. Practically, this means you might be present in consumer-facing LLM outputs but entirely absent in enterprise deployments. This is a major hurdle in the emerging field of AI content optimization.
HubSpot is the masterclass example here. When researchers from Semrush found that HubSpot consistently appeared in marketing-related LLM answers at a disproportionate rate, the reason was not mysterious.
HubSpot’s blog has published definitional content and structured how-to guides across thousands of topics for over a decade. These formats translate well into training data. When any model needs to generate a definition of “lead nurturing,” HubSpot’s phrasing often surfaces because the model was trained on it thousands of times. This is how you get cited by ChatGPT: by owning the vocabulary of your industry.
LLMs are not a monolith. They are a collection of different systems with different training histories and different output tendencies. ChatGPT coaches, Gemini calculates, Perplexity researches, and Claude operates.
The brands most likely to achieve AI visibility are those building structured, authoritative content now. This means owning the definitional territory and distributing content across channels that feed AI training data.
Ready to increase your AI visibility and capture more qualified leads?
Valasys Media’s content syndication and AI optimization services help B2B companies appear in the right AI-generated answers. Contact us to learn how our data-driven approach can accelerate your pipeline.
Not directly. Volume without structure and authority does not move the needle. LLMs favor content that is well-organized and cited by other credible sources. A single well-structured pillar page often outperforms ten thin posts.
You cannot edit the model, but you can shape the data it trains on. Publishing first-party research and original data carries significant weight because they become citation material for other publications, which then feeds the next round of training.
Different training data, fine-tuning approaches, and system prompt defaults. As the real examples above show, Claude might favor a formula while ChatGPT favors a metaphor. This means your content strategy needs format diversity to capture different model “personalities.”
Yes. Schema helps a model understand what a piece of content is, what entities it involves, and how it relates to other concepts. It reduces ambiguity, which models appreciate when they are trying to predict the most accurate “next token.”
The fundamentals of authority still apply, but the weighting is different. AI systems care less about backlink counts and more about conceptual authority and entity associations.
Compare AI Answers Side-by-Side
Different models = different answers. See the full picture before you decide.


