
Internet Stops: Did Cloudflare’s Routine Maintenance Trigger Worldwide Outage?
Cloudflare's 'internal service degradation' took down X, ChatGPT, and Canva with global 500 errors. We break down the failure, the unanswered maintenance question, and the risk of relying on single web giants.
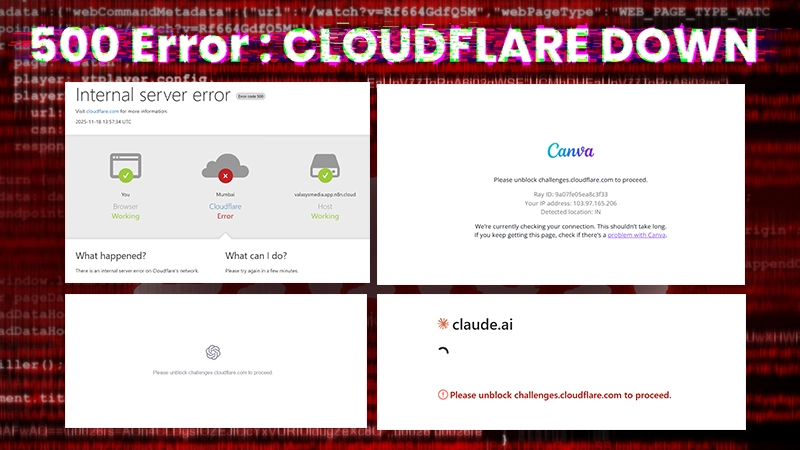
A huge part of the internet stopped working for many people today, Tuesday, November 18, 2025.
The problem was caused by a major failure at Cloudflare, a US company that helps keep millions of websites fast and safe. This failure made popular sites all over the world, including X (formerly Twitter), OpenAI’s ChatGPT and Canva show error pop up’s, telling users to try again later.
The Cloudflare Global Network suffered an unplanned ‘internal service degradation’, meaning a big problem started inside their own system. This led to widespread 500 errors (a server-side error code) for customers trying to visit websites.
The incident began around 11:48 UTC and quickly spread and impacted servers globally.
The outage was felt worldwide, with high numbers of error reports coming from the US, Europe, and Asia.
Outage tracker Downdetector saw a massive spike in reports, affecting services that use Cloudflare for speed and security.
A Cloudflare spokesperson confirmed they saw a “spike in unusual traffic to one of Cloudflare’s services” which caused the problems.
Was It Planned Maintenance? The Unanswered Question

The biggest question is Why this happened. Cloudflare stated that the core failure was an unexpected incident, not a planned shutdown.
However, the company’s engineers were scheduled to carry out maintenance in several data centers at the exact same time, including:
- Santiago (Chile)
- Buenos Aires (Argentina)
- Tahiti
- Atlanta
- Los Angeles
Official Website: Cloudflare Status
A spokesperson for Cloudflare noted that it was “not clear if their activities were related to the outage.”
Experts believe that the work being done during the scheduled maintenance, which involves moving website traffic around may have accidentally pushed a vulnerable part of the global network too hard, causing the larger, unplanned crash.
On the other hand, the company working quickly to fix the issue.
By early afternoon UTC, Cloudflare reported that they were “seeing services recover,” but warned that customers might still see “higher-than-normal error rates.”
The issue was identified, and a fix was being rolled out by their incident teams.
Cloudflare is still investigating the exact root cause of the problem to learn from the
This incident on the Cloudflare network comes just days after a massive Amazon Web Services (AWS) outage. This caused significant disruptions to services that rely on the AWS cloud. Both events highlight a major concern for the global digital world.
When huge parts of the internet rely on just a few companies like Cloudflare and Amazon to handle their data traffic, a small problem at one company can become a giant problem for the whole world.
Now the bigger question is, is it truly the safest or most convenient option to have such big chunks of the world’s data handled by a single company?
PS: This is a developing story. Stay tuned for further developments.

